Adversarial Robustness Probe: Stress-Testing NLP and Vision Models Before They Ship
NEO built a stress-testing framework that applies seven attack types to NLP and vision models, measures prediction flip rates, and generates shareable HTML reports for security, compliance, and model selection.
Problem Statement
We asked NEO to: Build a framework that stress-tests NLP and vision models with multiple adversarial attack types (typos, paraphrasing, FGSM, noise injection, etc.), measures flip rate (how often predictions change under perturbation), and produces structured HTML reports suitable for security review, compliance, and model selection—with all inference running locally.
Solution Overview
NEO built Adversarial Robustness Probe — a stress-testing framework that:
- Seven Attack Types — Typo, paraphrasing, character noise, token deletion, semantic drift, structural attacks (NLP); FGSM and noise injection (vision)
- Flip Rate Metric — Percentage of inputs where the model’s prediction changes after perturbation; simple, interpretable, deployment-relevant
- A–F Grading — 0–20% flip rate = A (reliable); 80–100% = D/F (critically unstable)
- Local-Only Inference — No external API calls; suitable for sensitive data and CI/CD
Processing 100 examples across multiple attack types takes 5–10 minutes depending on hardware. GPU is optional.
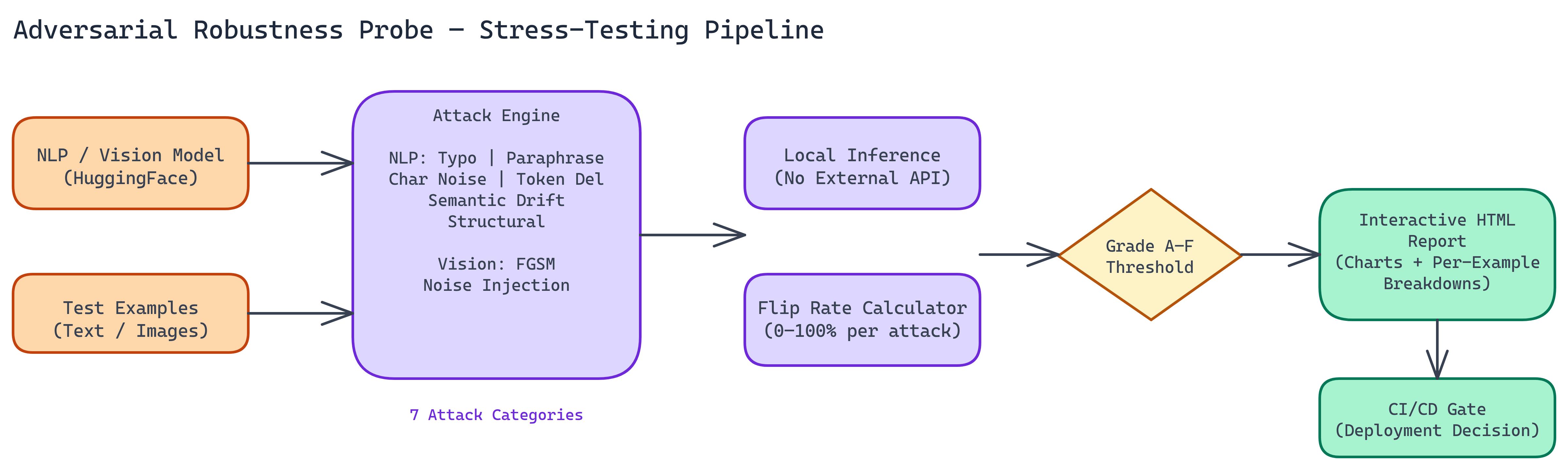
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Model & Data Load | Point tool at Hugging Face NLP model or torchvision vision model; provide test examples |
| 2. Attack Execution | Run each attack type (typo, paraphrase, FGSM, noise, etc.) on the input set |
| 3. Flip Rate Computation | Measure percentage of inputs where prediction changes after perturbation per attack type |
| 4. Grading & Report | Assign A–F grade; generate interactive HTML with flip rates, confidence changes, per-example breakdowns |
Attack Types
NLP: Typo attacks (transpositions, substitutions), paraphrasing, character noise, token deletion, semantic drift, structural (syntax/word order).
Vision: FGSM (gradient-based pixel perturbations), noise injection (compression, low light, sensor noise).
Repository & Artifacts
Generated Artifacts:
- Attack runners for NLP and vision models
- Flip rate computation and A–F grading
- Interactive HTML report with visualizations and per-example breakdowns
- Local-only inference pipeline; CI/CD-ready
Use Cases
- Security red-teaming — How the model behaves under deliberately crafted adversarial inputs
- Model selection — Robustness profiles when benchmark accuracy doesn’t separate candidates
- Regulatory compliance — Structured report for model risk assessments
- CI/CD — Robustness gate to catch regressions before production
Results & Best Practices
- Flip rate is the core metric: lower is more robust; use it for deployment decisions.
- A–F grading makes results accessible to non-technical stakeholders.
- Run probes during development to target data augmentation and training at specific weaknesses.
- Use the HTML report for engineering prioritization and compliance documentation.