Latest LLMs: Real-Life Task Evaluation Bench
NEO built a bench that runs new models on real-world style work: coding, reasoning, tools, and long docs. You compare models on tasks that feel like your product, not only leaderboard trivia.
Problem Statement
We asked NEO to standardize how we evaluate fresh LLM releases: same prompts, clear rubrics, and reports that spell out trade-offs before we ship.
Solution Overview
- Task suites: Curated scenarios with reference checks and LLM-as-judge where it helps.
- Model matrix: Swap endpoints and line up runs in one report.
- Regression tracking: Keep scores over time as vendors ship updates.
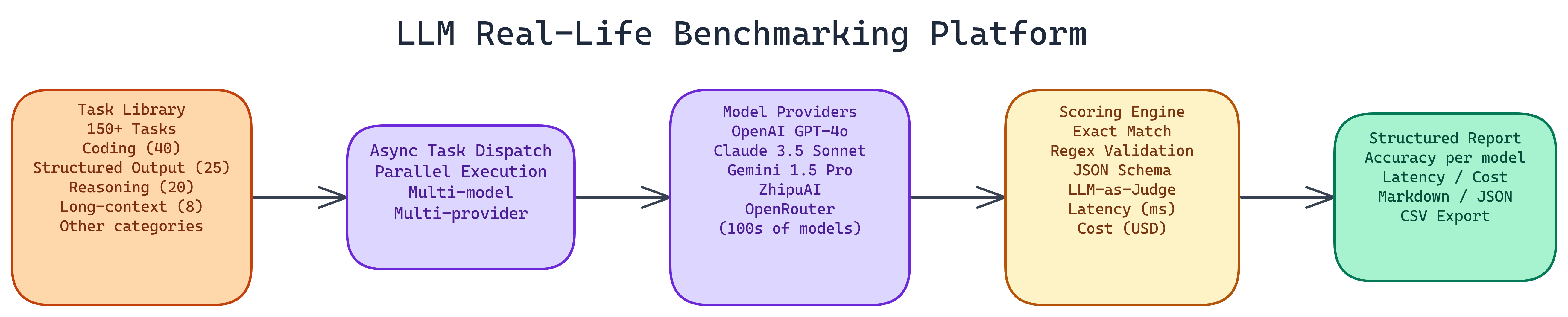
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Configure | Select models, API keys, and task packs |
| 2. Execute | Run prompts with retries and rate limiting |
| 3. Score | Automatic checks plus optional judge model |
| 4. Report | Side-by-side tables and cost estimates |
Repository & Artifacts
Generated Artifacts:
- Runnable benchmark CLI and JSON results
- Report templates for model selection reviews