Embedding Evaluator: Audit Embeddings Before They Break Your RAG
NEO put together a pipeline that scores embedding quality, spots drift, and compares vector stores. The goal is simple: help you trust retrieval and similarity search before it hits production.
Problem Statement
We asked NEO to give us tooling that evaluates embedding models and vector indexes. It should measure cluster coherence, neighbor stability, and semantic drift so engineers can catch weak vectors early, before users get weird RAG answers or broken deduping.
Solution Overview
NEO built an embedding audit framework that:
- Quality metrics: Intra-cluster consistency, silhouette-style separation, and nearest-neighbor overlap across runs.
- Drift detection: Compares current embeddings to a baseline (cosine shift, centroid movement).
- Report outputs: Structured summaries and plots you can drop into CI or share in review.
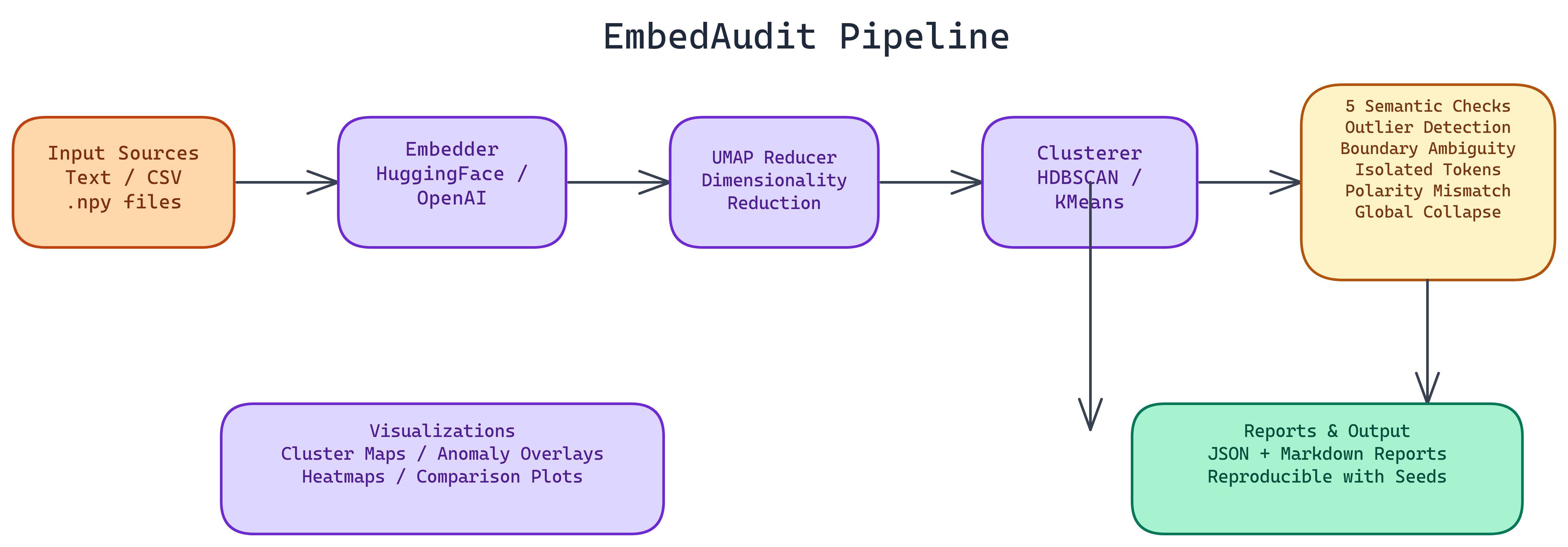
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Ingest | Load texts or vectors; optional label columns for supervised checks |
| 2. Encode | Run chosen sentence-transformer or API embedding model |
| 3. Score | Compute quality and drift metrics vs baseline or prior run |
| 4. Report | Export JSON/Markdown/HTML with flags for regressions |
Repository & Artifacts
Generated Artifacts:
- CLI and library for batch embedding evaluation
- Drift and quality dashboards (exportable)
- Baseline comparison for CI gates