AutoPrompter: Closed-Loop Autonomous Prompt Optimization
NEO built a closed loop around prompts: synthetic data, scoring, failure review, and a persistent ledger so you can tell whether a change actually helped.
Problem Statement
We asked NEO to split an Optimizer LLM (writes and revises prompts) from a Target LLM you are evaluating. Run batches, score with accuracy or semantic similarity, and log every iteration so comparisons stay fair and repeatable.
Solution Overview
NEO shipped AutoPrompter with:
- Dual-model setup: Optimizer (for example Gemini Flash) and Target (for example Qwen 3.5 9B) at different temperatures.
- Metrics: Classification accuracy or embedding similarity for open-ended tasks.
- Experiment ledger: JSON history with caps and summarization for long runs.
- YAML + CLI: Full config plus
--overridefor quick tweaks. - Backends: OpenRouter, Ollama, or llama.cpp from config.
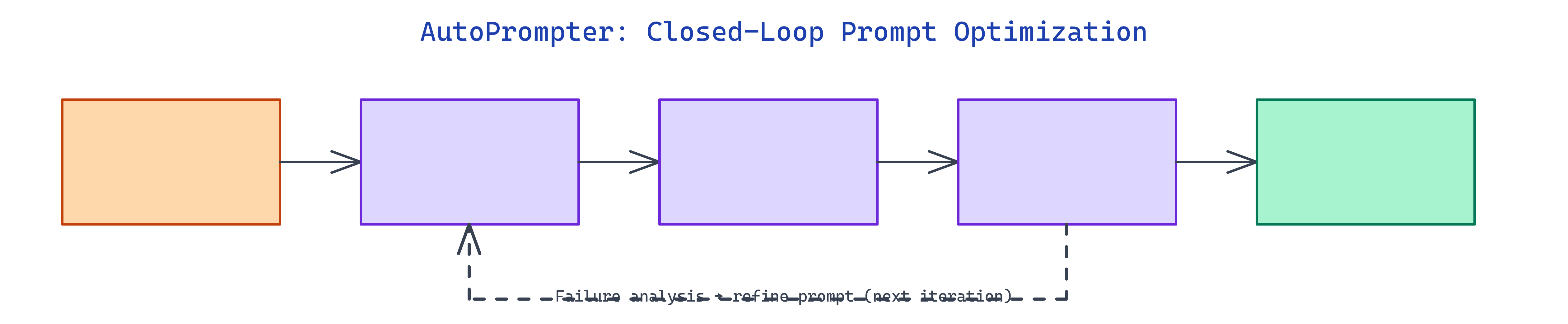
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Dataset | Optimizer generates synthetic examples for the task (e.g. classification) |
| 2. Execute | Target runs current prompt on the batch; scores recorded |
| 3. Stop or iterate | Stop if score ≥ convergence threshold or improvement < minimum delta |
| 4. Refine | Optimizer reads failure summaries and writes next prompt; ledger updated |
Repository & Artifacts
Generated Artifacts:
main.pyCLI with YAML config and overridesexperiment_ledger.jsonfor cross-session continuity- Example configs for sentiment, blogging, math, and reasoning tasks