Helix: Self-Healing CI/CD for Flaky Pipelines and Failed Deploys
NEO built an agent that watches CI/CD logs, sorts failures, and suggests fixes: retries, config tweaks, dependency bumps. The idea is to get pipelines healthy again without waking everyone on the team.
Problem Statement
We asked NEO to cut recovery time for build and deploy failures by automating triage and safe fixes inside whatever policy you set.
Solution Overview
- Signal ingest: GitHub Actions, GitLab CI, or generic webhooks.
- Root-cause hints: Pattern matching plus an LLM-friendly log summary.
- Actions: Open PRs with fixes, re-run jobs, or escalate when needed.
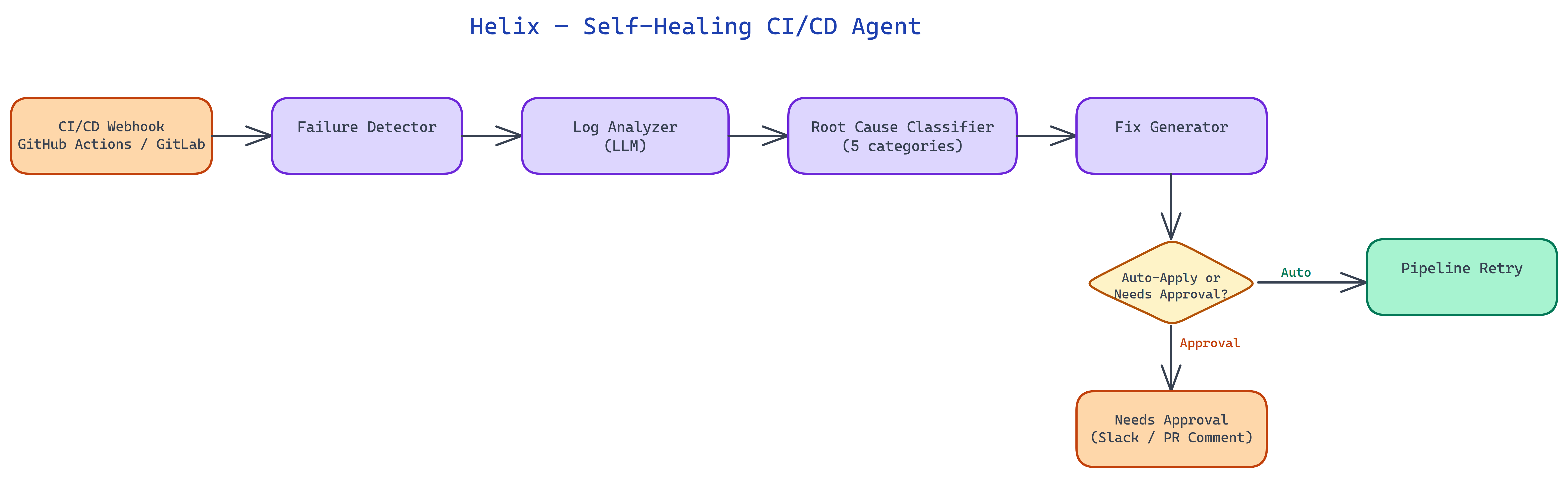
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Detect | Failure event captured from CI provider |
| 2. Classify | Map to known failure families (tests, infra, deps) |
| 3. Propose | Generate patch or retry plan with risk score |
| 4. Execute | Auto-apply within allowlist; else notify owner |
Repository & Artifacts
Generated Artifacts:
- CI webhook receiver and policy engine
- Playbooks for common flake patterns