Attention Head Visualiser: Mapping What Each Head in GPT-2 Actually Does
NEO built an attention head probe that automatically classifies GPT-2 attention heads into copying, induction, previous-token, and retrieval behaviors, then generates interactive HTML reports with heatmaps and head passport cards.
Problem Statement
We asked NEO to: Build a tool that automates attention head analysis for GPT-2—classifying each head into interpretable behavior types (copying, induction, previous-token, retrieval), scoring confidence per head, and producing interactive reports so teams can diagnose model behavior, compare architectures, and teach attention mechanics without writing custom code.
Solution Overview
NEO built the Attention Head Visualiser with:
- Four Head Behaviors — Copying (exact token reproduction), induction (pattern completion), previous-token (local syntax), retrieval (factual associations from context)
- Vectorized Scoring — Per-behavior scores 0–1; load ~2s (GPT-2 small) to <20s (1.5B); scoring adds <8s
- GPT-2 Variants — 124M, 355M, 774M, 1.5B; auto device (CUDA, MPS, CPU)
- Interactive HTML Reports — Heatmaps, head passport cards, summary statistics and layer breakdowns
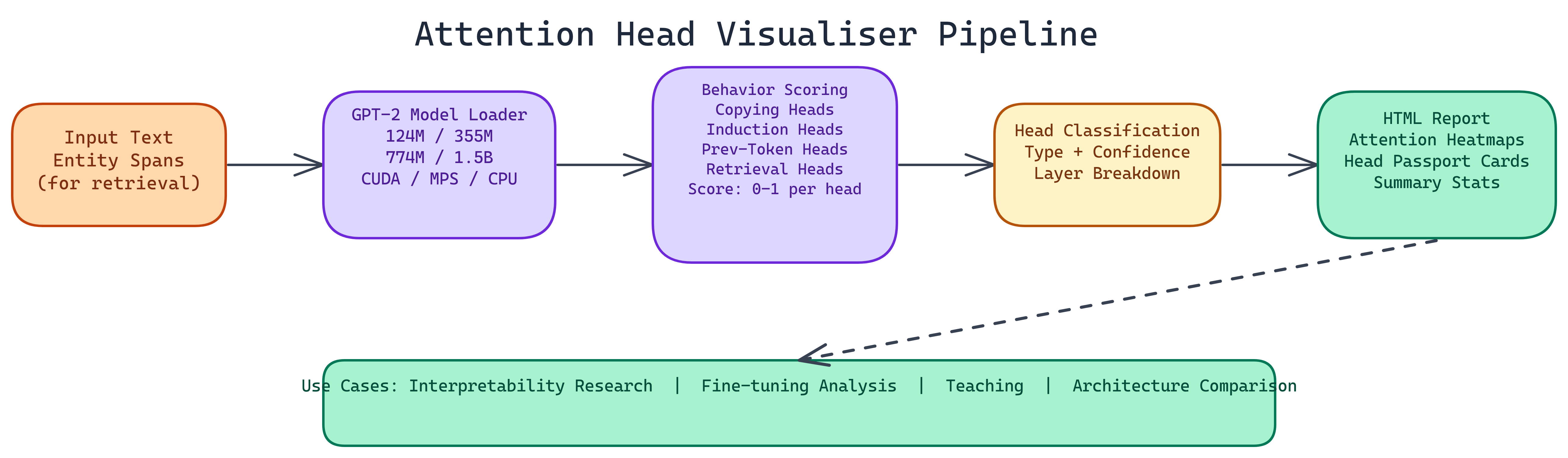
Workflow / Pipeline
| Step | Description |
|---|---|
| 1. Model Load | Load GPT-2 variant (124M–1.5B); auto-detect CUDA / MPS / CPU |
| 2. Behavior Scoring | Run vectorized scoring per behavior type (induction, previous-token, copying, retrieval with entity spans) |
| 3. Classification & Confidence | Assign each head to a behavior; attach confidence score |
| 4. Report Generation | Output HTML with heatmaps, passport cards, aggregate stats, layer breakdowns |
Head Behaviors Explained
- Copying — Attend to exact earlier tokens; propagate matches forward
- Induction — Complete “A B … A” → B; central to in-context learning
- Previous token — Attend to position i-1; local syntactic role
- Retrieval — Attend to entity/attribute spans for factual recall
Repository & Artifacts
Generated Artifacts:
- Model loading and behavior scoring modules
- Visualization layer (heatmaps, passport cards)
- CLI for input text, behavior types, entity spans, output path
- Six-module codebase; independently testable for new behavior types
Use Cases
- Interpretability research — Causal tracing and understanding specific outputs
- Fine-tuning analysis — Compare head behaviors before/after fine-tuning
- Teaching — Visual explanation of attention mechanisms
- Architecture comparison — Compare head behavior distributions across model sizes